
En este post vamos a hablar sobre un área muy influenciada por la inteligencia artificial como es la visión artificial, concretamente en lo que se denomina como segmentación de imágenes, para introducir posteriormente el uso del Deep Learning y, de forma más específica, las redes convolucionales y su potencial uso en este ámbito.
La segmentación de imágenes, en su sentido más estricto y convencional, no tiene por qué recurrir a ninguna estrategia de aprendizaje automático. Sin embargo, en la actualidad, debido al enorme auge del Deep Learning, la segmentación de imágenes ha mejorado notablemente gracias a la utilización de arquitecturas de redes profundas como es el caso de las redes convolucionales, muy utilizadas en el ámbito de análisis de imágenes.
Concretamente, hablaremos sobre qué es la segmentación y de su enorme importancia en la visión artificial, a continuación, resumiremos brevemente algunos conceptos de redes neuronales y las ideas fundamentales del Deep Learning, para más tarde pasar a hablar de las redes convolucionales, sus ventajas frente a otras arquitecturas de red y de cómo se pueden utilizar en el contexto de la segmentación.
¿Qué es la segmentación de imágenes?
Imagínate que tienes un conjunto de imágenes del fondo del mar con peces y, suponiendo que saber el número de ejemplares que hay en una zona es relevante para un estudio científico, quieres obtener un método automático que te permita contarlos.
Esto nos ahorraría muchísimo tiempo en el caso de tener, por ejemplo, 500 imágenes. En cada imagen, la cuenta nos podría llevar 2 minutos, por poner un tiempo razonable. Ahora imagínate escalar eso a 2 minutos por 500 imágenes. Probablemente te llevaría días e incluso semanas, porque una tarea tan monótona te acabaría agotando y no podrías hacer todo de una tirada.
Para conseguir esto, las estrategias de visión artificial son, sin ninguna duda, lo más apropiado para el problema. Pero… ¿cómo podríamos conseguir resolver este problema tan concreto? Teniendo en cuenta que en una imagen del fondo marino hay muchas cosas, para el método de visión no sería trivial encontrar los peces. Para ello, necesitaría eliminar todos los datos que no sean relevantes y centrarse exclusivamente en aquello que sea un pez.
Esto se puede conseguir por medio de la segmentación. La segmentación es básicamente obtener la silueta de los objetos de interés que queramos extraer en una imagen. En el caso de este ejemplo, estaríamos buscando obtener la silueta de los peces. Al centrarnos exclusivamente en la silueta de los peces, estaríamos eliminando todo aquello que no fuese relevante y que, de este modo, estaría introduciendo ruido al sistema.
Dificultades de la segmentación
La segmentación no es un proceso para nada sencillo, en ninguna de sus partes, es decir, ni en la de elegir el mejor método de segmentación ni a la hora de validar. De hecho, hemos hecho manualmente esa segmentación manual que se muestra más arriba y nos hemos dado cuenta de algunos problemas importantes que se pueden dar a la hora de analizar este tipo de imágenes, unas dificultades que podrían hacer incluso inviable el conteo preciso de los peces.
Observamos que estas imágenes se caracterizan por tener a muchos peces que se superponen sobre otros, lo cual hace difícil hacerle entender al método si ahí hay un pez o hay varios. Del mismo modo, hay peces que quedan parcialmente ocultos por algún elemento submarino, haciendo todavía más difícil ese conteo preciso.
Probablemente dirás «qué ejemplo tan mal escogido». Pues lo cierto es que nos ha parecido interesante, ya que representa muy bien los problemas a los que nos enfrentamos cuando queremos desarrollar un sistema de visión artificial. A menudo, nos encontramos ejemplos como un caballo en un campo, en una imagen muy bien hecha, con buen contraste y con el caballo bien encuadrado. Pero lo cierto es que, en la vida real, debemos prepararnos para cualquier problema que pueda surgir.
¿Qué metodos de segmentación existen en la literatura?
Existe una multitud de métodos de segmentación. Algunos de los más destacables son la umbralización, el algoritmo split and merge, los algoritmos de rellenado de regiones, el algoritmo de watershed o los modelos deformables. Cada uno de ellos, funcionará bien o no en un problema concreto. La única forma de conocerlo es validándolo de una manera conveniente.
Cabe destacar que los principales métodos de segmentación de imágenes se pueden encontrar ya implementados en librerías como OpenCV o Scikit-Image, las cuales están disponibles para Python y son muy fácilmente instalables con sistemas de gestión de paquetes como es el caso de pip.
¿Cómo se valida y por qué es tan complicado?
Para validar la segmentación, tiene que haber una segmentación de referencia, lo que se denomina generalmente como un ground truth. Este ground truth se tiene que obtener de forma manual, pintando la silueta de los objetos de interés con un color uniforme. Pensarás que esto es un proceso muy tedioso… y efectivamente, lo es.
A menudo, la obtención de estos ground truths se denomina «etiquetado manual de imágenes» o, en este caso, «segmentación manual de imágenes» y, dado que es un proceso tan tedioso, existe una falta de datos de este tipo. Es muy común que, por ejemplo, de esas 500 imágenes mencionadas solo se hayan etiquetado 50. Esto es un grave problema para las redes de Deep Learning, como veremos más adelante.
Para que te hagas a la idea, nosotros hemos segmentado manualmente la imagen que se mostraba más arriba de una forma bastante burda y ya nos ha resultado bastante tedioso. Además, estamos seguros de que, durante el proceso, se nos ha escapado algún pez, que probablemente caiga en una zona de muy bajo brillo. Nuevamente, esto es significativo de lo complicado que resulta segmentar manualmente imágenes y, sobre todo, lo tedioso que llegaría a ser en caso de que no fuera 1 si no muchísimas más.
El caso es que en el hipotético caso de que tengamos un suficiente número de imágenes etiquetadas, este ground truth será comparado con la segmentación realizada por el método de visión artificial, por medio de una serie de métricas que evaluarán la precisión con la que el sistema segmenta.
La segmentación, el machine learning y la importancia de las redes convolucionales
Como en cualquier paso de la visión artificial, el machine learning puede ser utilizado como alternativa a otras estrategias más clásicas como las anteriormente mencionadas (umbralización, growing regions, modelos deformables…) en el contexto de la segmentación de imágenes.
Además, el Deep Learning se ha presentado como una solución mucho más óptima e inmediata para realizar la segmentación de una imagen. En visión artificial, concretamente, una arquitectura de red profunda muy utilizada es la de las redes convolucionales.
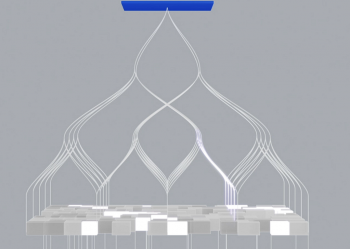
Esta estrategia intenta solventar el gran tamaño que podrían tener las redes totalmente conectadas en caso de utilizar alguna arquitectura profunda con una enorme cantidad se capas. En las redes fully connected, todas las neuronas de una capa se conectan con todas las neuronas de la capa siguiente. En lugar de esto, las redes convolucionales utilizan un esquema de conectividad local. Eso permite reducir el número de conexiones entre las neuronas y reducir el tamaño de las redes profundas, que ya de por sí consumen una enorme cantidad de memoria.
La figura que se muestra más arriba, de una típica arquitectura de red convolucional, tiene unas capas que se llaman «convolution», otras que se llaman «pooling» y una capa totalmente conectada al final. Esto es muy común en las redes convolucionales que se usan para clasificación.
Por una parte, las capas de «convolution» permiten extraer características de manera automática de las imágenes. Por otra parte, las capas de «pooling» reducen la dimensionalidad de la imagen poco a poco, para llegar finalmente a un vector de características que representará la entrada a una red «fully connected». La ventaja de hacer esto es que, aunque tengamos una red profunda, la única red fully connected tendrá el tamaño equiparable al de un perceptrón multicapa, es decir, algo mucho más asumible que una red fully connected con cientos de capas.
Capas convolucionales
Este esquema de conectividad local se consigue por medio de las convoluciones (de ahí recibe el nombre la arquitectura de red). Para simplificar, una convolución es una operación matricial que, en el contexto de las imágenes, permite realizar un filtrado sobre las mismas. En otras palabras, por medio de una convolución puedes realizar filtros muy útiles como eliminar toda la información que no sea un borde o difuminar la imagen.
La idea de la conectividad local es que un filtro convolucional es una matriz de tamaño relativamente pequeño que se aplica a modo de ventana deslizante sobre toda la imagen. De este modo, un solo kernel representará a un filtro.
La idea de todo esto no es solo reducir el tamaño de la arquitectura a nivel de conexiones entre neuronas, si no también conseguir un modelo de aprendizaje que sea capaz de aprender a filtrar las características más relevantes de una imagen de modo totalmente automático. De hecho, las redes convolucionales se caracterizan por tener una enorme cantidad de filtros diferentes.
A nivel de optimización de red neuronal, todo esto significa que el modelo actualizará los coeficientes del kernel convolucional para filtrar las imágenes del modo que el modelo considera oportuno.
¿Cómo ayudan las redes convolucionales a segmentar imágenes?
La idea final de utilizar una red convolucional para segmentar es tener un sistema al que le pases una imagen y que te devuelva otra imagen con los objetos de interés segmentados. Esto es un ejemplo de estrategia end-to-end. Para este caso, es muy importante disponer de un ground truth, ya que el modelo aprenderá cómo debe segmentar la imagen a partir de este ground truth.
En contraste con la red convolucional presentada anteriormente, que estaba destinada a clasificación, la red que aquí se presenta es una fully convolutional, de tal forma que no tiene ninguna capa totalmente conectada.
Esto es muy ventajoso ya que, entre otras cosas, nos permite que el tamaño de la imagen de entrada sea variable ya que al tener una capa totalmente conectada lo más probable es que la red se entrene con un tamaño de imagen fijo y que solo se le pueda pasar una imagen de ese mismo tamaño en la fase de predicción (es decir, una vez que estamos usando el modelo ya entrenado).
Este tipo de arquitecturas totalmente convolucionales para tareas como segmentación, se caracterizan por tener dos partes: el encoder y el decoder. El encoder reduce la dimensionalidad de la imagen de entrada hasta llegar a un vector de características. Por su parte, el decoder utiliza ese vector de características como entrada (que en la figura de abajo se denomina como latent representation) y aumenta poco a poco su dimensionalidad hasta llegar a la imagen de salida, que será la correspondiente a la segmentación.
Escasez de datos etiquetados
Y aquí es donde entramos en el problema de la escasez de datos etiquetados manualmente que mencionábamos unos cuantos párrafos más atrás. Los modelos de aprendizaje profundo necesitan de una enorme cantidad de datos para ser entrenados, en general.
En los últimos años, se han hecho muchos esfuerzos para solventar ese problema. Para ello, se pueden utilizar estrategias como el data augmentation, que básicamente pretende aumentar el tamaño de un conjunto de imágenes de manera artificial, es decir, sin necesidad de añadir ejemplos etiquetados nuevos.
El data augmentation clásico utiliza transformaciones triviales como rotaciones aleatorias, traslaciones o cambios de intensidad de los píxeles, pero cabe destacar que, en los últimos años, ha cobrado mucha importancia la generación de imagen sintética, con las redes generativas antagónicas (GAN) como una de la estrategias más utilizadas para tal fin.
Con todas las ideas mencionadas hasta ahora en mente y, conociendo los conceptos fundamentales sobre redes neuronales, el entrenamiento de una red convolucional es muy trivial. Sencillamente, le pasaremos una imagen al sistema, obtendremos una salida y la compararemos con su correspondiente ground truth. En esa comparación, se utilizará una función de error cuyo valor será retropropagado a los pesos de la red para que poco a poco su salida se optimice y alcance el comportamiento deseado.
Resumen
En resumidas cuentas, la segmentación de imágenes es un proceso de la visión artificial con el cual nos quedamos con la información que nos importa de una imagen para un problema concreto, eliminando cualquier otra cosa. Generalmente, esta segmentación será representada con una nueva imagen donde solo se puedan ver las siluetas de los objetos de interés.
Para la segmentación de imágenes, es muy interesante poder utilizar diferentes modelos de machine learning. Existen algunas aproximaciones convencionales que son un poco más rudimentarias y menos intuitivas.
Sin embargo, en la actualidad, el auge se encuentra en el Deep Learning que, con las arquitecturas de red convolucionales, es capaz de recibir una imagen como entrada y devolver directamente la segmentación a la salida.
Es muy importante disponer de datos etiquetados manualmente pero, por desgracia, es muy común que esto no sea así. Para evitarlo, se puede recurrir a estrategias de data augmentation, para incrementar el tamaño del conjunto de imágenes original de manera totalmente artificial, es decir, sin necesidad de etiquetar nuevos ejemplos de imágenes.
Fuentes
(Chen et. al, 2017) – L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation,” arXiv preprint arXiv:1706.05587, 2017.
(LeCun et. al, 1998) – Y. LeCun, L. Bottou, Y. Bengio, P. Haffner et al., “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
(Badrinarayanan et. al, 2017) – V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image segmentation,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 12, pp. 2481–2495, 2017
(Minaee et. al, 2021) – Minaee, Shervin, et al. «Image segmentation using deep learning: A survey.» IEEE Transactions on Pattern Analysis and Machine Intelligence (2021).
Créditos
Daniel Iglesias es informático y amplio conocedor del ámbito del aprendizaje automático y la visión artificial.

















{kind=link}